本文共 23561 字,大约阅读时间需要 78 分钟。
一、常见的表单验证插件
在项目开发过程中,我们需要对前台输入的一些数据进行校验,以到我我们要求的格式,这就难免要写很多正则表单式来进行判断,这是一件很费时的时,所有就出现了了一些表单验证框架,以下几种,是常见的:
1、: 一款历史悠久的Jquery插件
2、: 也是一款强大的验证框架
3、: 号称一句代码就能实现验证
二、jQuery Validate简介
官网地址:
Github地址:
在线文档:
JQuery Validation插件作为式历史悠久的jQuery插件之一,经过了全球各种项目的验证,得到了很多WEB开发者的好评,作为一个表单验证的解决方案,Validation有很多的优点,比如: 1.内置验证规则:拥有必填、数字、email、url和信用卡号码等内置验证规则; 2.自定义验证规则:可以很方便地自定义验证规则(通过$.validator.addMethod(name,method,message)实现); 3.简单强大的验证信息提示:默认了验证信息提示,并提供自定义覆盖默认信息提示的功能(通过设置插件中的message参数来实现); 4.实时验证:可以通过keyup或blur事件触发验证,而不仅仅在表单提交的时候验证。 5.异步验证: 用ajax实现了服务器端远程验证
三、框架源码
去官网下载最新的JQuery Validation插件,下载下来之后解压有如下内容:
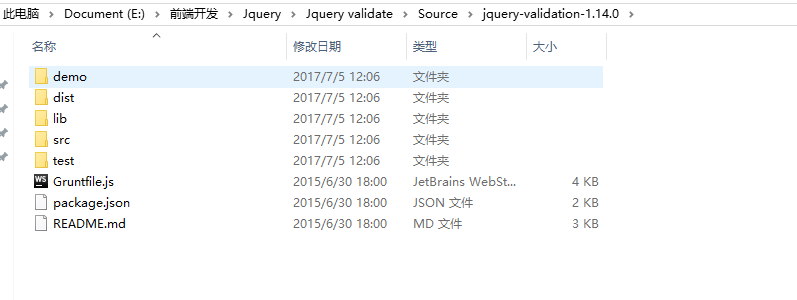
它里面提供了一些DEMO:
我将它翻译成功了中文:
▲ 合成的例子
errorcontainer-demo.html 操作中的错误消息容器 custom-messages-data-demo.html 自定义消息作为元素数据 radio-checkbox-select-demo.html 单选和复选框按钮验证表单 ajaxSubmit-integration-demo.html 与表单插件集成(AJAX提交) custom-methods-demo.html 自定义方法和消息显示. dynamic-totals.html 动态表单 themerollered.html 使用jQuery用户界面设计的表单 tinymce TinyMCE3 Demo tinymce4 TinyMCE4 Demo file_input.html 文件输入 jquerymobile.html jQuery Mobile表单验证 errors-within-labels.html 在字段标签中显示错误 requirejs/index.html 通过RequireJS加载 ▲实际的例子 milk --目录 Remember The Milk signup form marketo --目录 Marketo signup form multipart --目录 购买并出售一套房子 captcha --目录 远程验证验证 ▲测试套件 ../test/ 验证测试
四、使用前提
在引入jquery validate插件前,需要先引入它所依赖的文件jquery.js
五、默认校验规则
jquery validate提供了一些默认的校验规则如下:
(1)、required:true 必输字段 (2)、remote:"remote-valid.jsp" 使用ajax方法调用remote-valid.jsp验证输入值 (3)、email:true 必须输入正确格式的电子邮件 (4)、url:true 必须输入正确格式的网址 (5)、date:true 必须输入正确格式的日期,日期校验ie6出错,慎用 (6)、dateISO:true 必须输入正确格式的日期(ISO),例如:2009-06-23,1998/01/22 只验证格式,不验证有效性 (7)、number:true 必须输入合法的数字(负数,小数) (8)、digits:true 必须输入整数 (9)、creditcard:true 必须输入合法的信用卡号 (10)、equalTo:"#password" 输入值必须和#password相同 (11)、accept: 输入拥有合法后缀名的字符串(上传文件的后缀) (12)、maxlength:5 输入长度最多是5的字符串(汉字算一个字符) (13)、minlength:10 输入长度最小是10的字符串(汉字算一个字符) (14)、rangelength:[5,10] 输入长度必须介于 5 和 10 之间的字符串")(汉字算一个字符) (15)、range:[5,10] 输入值必须介于 5 和 10 之间 (16)、max:5 输入值不能大于5 (17)、min:10 输入值不能小于10
五、默认提示
jquery validate默认的提示全是英文的,提示的信息如下,在jquery.validate.js中:
messages: { required: "This field is required.", remote: "Please fix this field.", email: "Please enter a valid email address.", url: "Please enter a valid URL.", date: "Please enter a valid date.", dateISO: "Please enter a valid date ( ISO ).", number: "Please enter a valid number.", digits: "Please enter only digits.", creditcard: "Please enter a valid credit card number.", equalTo: "Please enter the same value again.", maxlength: $.validator.format( "Please enter no more than {0} characters." ), minlength: $.validator.format( "Please enter at least {0} characters." ), rangelength: $.validator.format( "Please enter a value between {0} and {1} characters long." ), range: $.validator.format( "Please enter a value between {0} and {1}." ), max: $.validator.format( "Please enter a value less than or equal to {0}." ), min: $.validator.format( "Please enter a value greater than or equal to {0}." )} jQuery Validate提供了中文信息提示包,位于下载包的 dist/localization/messages_zh.js,内容如下:
(function( factory ) { if ( typeof define === "function" && define.amd ) { define( ["jquery", "../jquery.validate"], factory ); } else { factory( jQuery ); }}(function( $ ) {/* * Translated default messages for the jQuery validation plugin. * Locale: ZH (Chinese, 中文 (Zhōngwén), 汉语, 漢語) */$.extend($.validator.messages, { required: "这是必填字段", remote: "请修正此字段", email: "请输入有效的电子邮件地址", url: "请输入有效的网址", date: "请输入有效的日期", dateISO: "请输入有效的日期 (YYYY-MM-DD)", number: "请输入有效的数字", digits: "只能输入数字", creditcard: "请输入有效的信用卡号码", equalTo: "你的输入不相同", extension: "请输入有效的后缀", maxlength: $.validator.format("最多可以输入 {0} 个字符"), minlength: $.validator.format("最少要输入 {0} 个字符"), rangelength: $.validator.format("请输入长度在 {0} 到 {1} 之间的字符串"), range: $.validator.format("请输入范围在 {0} 到 {1} 之间的数值"), max: $.validator.format("请输入不大于 {0} 的数值"), min: $.validator.format("请输入不小于 {0} 的数值")});})); 可以将该本地化信息文件 messages_zh.js 引入到页面:
还可以直接扩展:
$.extend($.validator.messages, { required: "必选字段", remote: "请修正该字段", email: "请输入正确格式的电子邮件", url: "请输入合法的网址", date: "请输入合法的日期", dateISO: "请输入合法的日期 (ISO).", number: "请输入合法的数字", digits: "只能输入整数", creditcard: "请输入合法的信用卡号", equalTo: "请再次输入相同的值", accept: "请输入拥有合法后缀名的字符串", maxlength: $.validator.format("请输入一个长度最多是 {0} 的字符串"), minlength: $.validator.format("请输入一个长度最少是 {0} 的字符串"), rangelength: $.validator.format("请输入一个长度介于 {0} 和 {1} 之间的字符串"), range: $.validator.format("请输入一个介于 {0} 和 {1} 之间的值"), max: $.validator.format("请输入一个最大为 {0} 的值"), min: $.validator.format("请输入一个最小为 {0} 的值")}); 一般推荐使用第一种。 六、使用方式
校验规则常用的有三种方法:
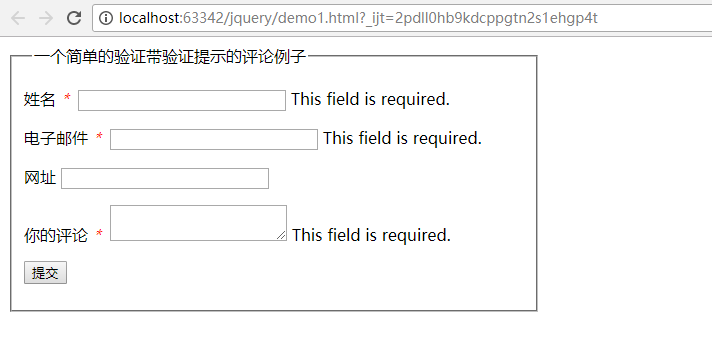
1、Class用法,将校验规则写到Class中
Class用法,讲校验规则写到Class中
效果如下:
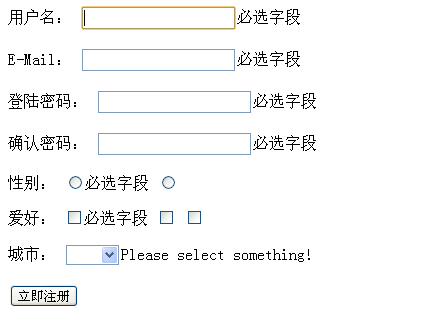
2、metadata用法,将校验规则写到控件中
这种方法貌似在最新的版本中用不了。。。
效果大概如下:metadata用法,将校验规则写到控件中
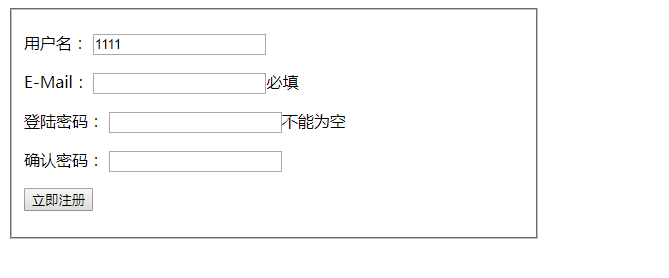
3、将校验规则写到js代码中
效果如下:metadata用法,将校验规则写到控件中
七、常用方法及注意问题
暂时还没整理好。。。
八、动态添加与异步验证用户名
动态的往表单里添加验证:
效果如下:
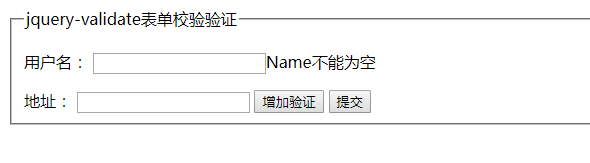
默认只有用户名有验证效果,地址没有效果,点击增加验证之后,地址就有验证效果了。
代码如下
Title
异步验证用户名:
效果如下:
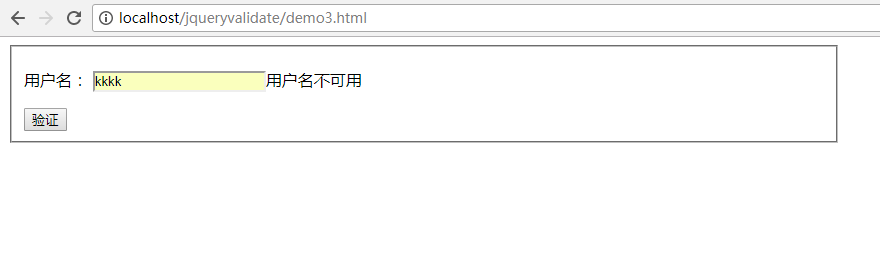
当输入的用户名存在时会提示用户名不可用
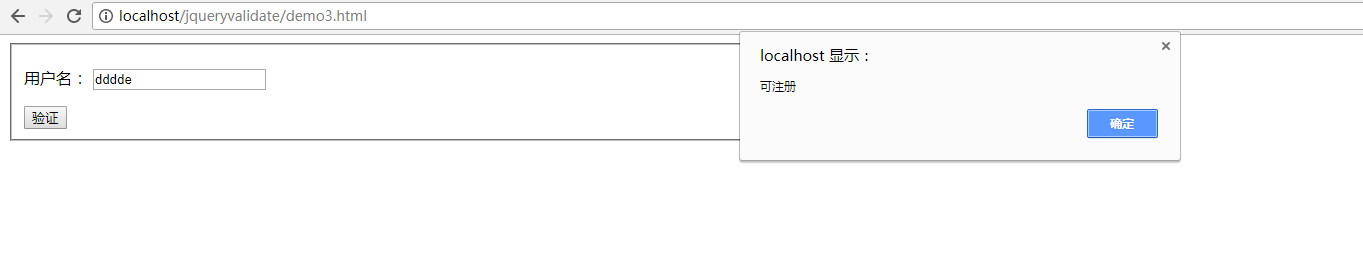
如何不存在是会提示可以注册:
前端代码
metadata用法,将校验规则写到控件中
后端代码:
九、扩展Validate
扩展文件为jquery.validate.extension.js
// * 唯一性校验方法,后台返回"1"或"0"// * validateName:该校验规则的Name,在校验规则中使用// * url: Ajax请求url// * extend: 向后台传递的附加字段,需要传给后台的其他输入元素的id数组// * message: 控件值不唯一时,页面显示的信息// $.extend({ uniqueValidate: function(validateName, url, extend, message) { jQuery.validator.addMethod(validateName, function(value, element) { var data = new Object(); $.each(extend, function(i, o) { data[o] = $('#' + o).val(); }); data[element.id] = value; var returnBoolean = false; $.ajax({ url: url, data: data, cache: false, async: false, type: 'GET', dataType: 'text', timeout: 10000, error: function() { jQuery.validator.messages[validateName] = '对不起,服务器响应超时,请联系管理员'; }, success: function(result) { if(result == '1') { returnBoolean = true; } else { returnBoolean = false; } } }); return returnBoolean; }, message); }, cnLength:function(validateName,minLen,maxLen,message){ jQuery.validator.addMethod(validateName, function(value, element) { var length = value.length; minLen = !minLen ? 0 : parseInt(minLen); maxLen = !maxLen ? 0 : parseInt(maxLen); for(var i = 0; i < value.length; i++) { if(value.charCodeAt(i) > 127) { length++; } } if(minLen==0 && maxLen==0){ return this.optional(element); }else if(minLen==0 && maxLen!=0){ return length <= maxLen; }else if(minLen!=0 && maxLen==0){ return length >= minLen; }else{ return length >= minLen && length <= maxLen; } }, message); }, idIsBlack:function(validateName,id,message){ jQuery.validator.addMethod(validateName, function(value, element) { var returnBoolean = false; if(jQuery("#"+id).val() !=''){ returnBoolean = true; } return returnBoolean; }, message); }});// * jQuery validation 验证类型扩展// // 邮政编码验证jQuery.validator.addMethod("isZipCode", function(value, element) { var zip = /^[0-9]{6}$/; return this.optional(element) || (zip.test(value));}, "请正确填写您的邮政编码!");// 身份证号码验证jQuery.validator.addMethod("isIdCardNo", function(value, element) { var idCard = /^(^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$)|(^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])((\d{4})|\d{3}[Xx])$)$/; return this.optional(element) || (idCard.test(value));}, "请输入正确的身份证号码!");// 手机号码验证jQuery.validator.addMethod("isMobile", function(value, element) { var length = value.length; return this.optional(element) || (length == 11 && /^1[3|4|5|7|8][0-9]\d{4,8}$/.test(value));}, "请正确填写您的手机号码!");// 电话号码验证jQuery.validator.addMethod("isPhone", function(value, element) { var tel = /^((0[0-9]{2,3}\-)?([2-9][0-9]{6,7})+(\-[0-9]{1,4})?)|(((\(\d{3}\))|(\d{3}\-))?(1[358]\d{9}))$/g; return this.optional(element) || (tel.test(value));}, "请正确填写您的电话号码!");// 用户名字符验证jQuery.validator.addMethod("userName", function(value, element) { return this.optional(element) || /^[\u0391-\uFFE5\w]+$/.test(value);}, "用户名只能包括中文字、英文字母、数字和下划线!");// 联系电话(手机/电话皆可)验证jQuery.validator.addMethod("isTel", function(value,element) { var length = value.length; var mobile = /^(((13[0-9]{1})|(15[0-9]{1})|(18[0-3,5-9]{1}))+\d{8})$/; var tel = /^(0[0-9]{2,3}\-)?([2-9][0-9]{6,7})+(\-[0-9]{1,4})?$/; return this.optional(element) || ((tel.test(value)&&length <= 12) || (mobile.test(value) &&length == 11));}, "请正确填写您的联系电话!");// IP地址验证jQuery.validator.addMethod("ip", function(value, element) { return this.optional(element) || /^(([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))\.)(([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))\.){2}([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))$/.test(value);}, "请填写正确的IP地址!");// 含有中文的最大字符长度校验jQuery.validator.addMethod("cnRangelength", function(value, element, param) { var length = value.length; for(var i = 0; i < value.length; i++) { if(value.charCodeAt(i) > 127) { length++; } } return this.optional(element) || ( length >= param[0] && length <= param[1] );}, jQuery.validator.format("请输入一个长度介于 {0} 和 {1} 之间的字符串(一个中文长度为2)"));// 中文字符2~8jQuery.validator.addMethod("chrnum1", function(value, element) { var length = value.length; for(var i = 0; i < value.length; i++) { if(value.charCodeAt(i) > 127) { length++; } } return this.optional(element) || ( length >= 4 && length <= 16 );}, "用户名密码长度为4-16个英文字符个英文字符个英文字符个英文字符个英文字符个英文字符");// 只允许输入英文字符,数字和下划线jQuery.validator.addMethod("charNo",function(value,element) { var length = value.length; var your_tel =/[/^\W+$/]/g; return this.optional(element) || (!your_tel.test(value));},"请输入英文字符、数字、下划线!");// 只允许输入中文、英文字符,数字和下划线jQuery.validator.addMethod("stringCheck", function(value, element) { return this.optional(element) || /^(\w|[\u4E00-\u9FA5]|@)*$/.test(value);}, "只能包括中英文、数字、@和下划线");// 只能包括中英文字母、数字、下划线和中文标点符号jQuery.validator.addMethod("textareaCheck", function(value, element) { return this.optional(element) || /^(\w|[\u4E00-\u9FA5]|[,。“;!?@、])*$/.test(value);}, "只能包括中英文字母、数字、下划线和中文标点符号");// 手机号码验证jQuery.validator.addMethod("mobile", function(value, element) { var length = value.length; var mobile = /^[1][358]\d{9}$/; return this.optional(element) || (length == 11 && mobile.test(value));}, "手机号码格式错误");// 电话号码验证jQuery.validator.addMethod("phone", function(value, element) { var tel = /^(0[0-9]{2,3}(\-)?)?([2-9][0-9]{6,7})+(\-[0-9]{1,4})?$/; return this.optional(element) || (tel.test(value));}, "电话号码格式错误");// 邮政编码验证jQuery.validator.addMethod("zipCode", function(value, element) { var tel = /^[0-9]{6}$/; return this.optional(element) || (tel.test(value));}, "邮政编码格式错误");// QQ号码验证jQuery.validator.addMethod("qq", function(value, element) { var tel = /^[1-9]\d{4,9}$/; return this.optional(element) || (tel.test(value));}, "qq号码格式错误");// 字母和数字的验证jQuery.validator.addMethod("chrnum", function(value, element) { var chrnum = /^([a-zA-Z0-9]+)$/; return this.optional(element) || (chrnum.test(value));}, "只能输入数字和字母(字符A-Z, a-z, 0-9)");// 中文的验证jQuery.validator.addMethod("chinese", function(value, element) { var chinese = /^[\u4e00-\u9fa5]+$/; return this.optional(element) || (chinese.test(value));}, "只能输入中文");// 中文英文的验证jQuery.validator.addMethod("chineseEnglish", function(value, element) { var chinese = /^[\u4e00-\u9fa5_a-zA-Z]+$/; return this.optional(element) || (chinese.test(value));}, "只能输入中文或英文");// 以汉字或字母开头jQuery.validator.addMethod("firstString", function(value, element) { var firstString = /^[\u4e00-\u9fa5a-zA-Z][\u4e00-\u9fa5a-zA-Z\d]+$/; return this.optional(element) || (firstString.test(value));}, "只能以汉字或字母开头");// 以字母开头的字符串jQuery.validator.addMethod("firstChar", function(value, element) { var firstChar = /^[a-zA-Z].*$/; return this.optional(element) || (firstChar.test(value));}, "只能以字母开头的字符串");// 正整数验证jQuery.validator.addMethod("positiveinteger", function(value, element) { var aint=parseInt(value); return aint>0&& (aint+"")==value; }, "只能输入正整数");//绑定验证提示消息关闭事件处理方法$('.error-close').on('click',function(){ $(this).parent().parent().remove();}); 还有这种扩展:
/***************************************************************** * jQuery Validate扩展验证方法*****************************************************************/$(function(){ // 判断整数value是否等于0 jQuery.validator.addMethod("isIntEqZero", function(value, element) { value=parseInt(value); return this.optional(element) || value==0; }, "整数必须为0"); // 判断整数value是否大于0 jQuery.validator.addMethod("isIntGtZero", function(value, element) { value=parseInt(value); return this.optional(element) || value>0; }, "整数必须大于0"); // 判断整数value是否大于或等于0 jQuery.validator.addMethod("isIntGteZero", function(value, element) { value=parseInt(value); return this.optional(element) || value>=0; }, "整数必须大于或等于0"); // 判断整数value是否不等于0 jQuery.validator.addMethod("isIntNEqZero", function(value, element) { value=parseInt(value); return this.optional(element) || value!=0; }, "整数必须不等于0"); // 判断整数value是否小于0 jQuery.validator.addMethod("isIntLtZero", function(value, element) { value=parseInt(value); return this.optional(element) || value<0; }, "整数必须小于0"); // 判断整数value是否小于或等于0 jQuery.validator.addMethod("isIntLteZero", function(value, element) { value=parseInt(value); return this.optional(element) || value<=0; }, "整数必须小于或等于0"); // 判断浮点数value是否等于0 jQuery.validator.addMethod("isFloatEqZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value==0; }, "浮点数必须为0"); // 判断浮点数value是否大于0 jQuery.validator.addMethod("isFloatGtZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value>0; }, "浮点数必须大于0"); // 判断浮点数value是否大于或等于0 jQuery.validator.addMethod("isFloatGteZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value>=0; }, "浮点数必须大于或等于0"); // 判断浮点数value是否不等于0 jQuery.validator.addMethod("isFloatNEqZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value!=0; }, "浮点数必须不等于0"); // 判断浮点数value是否小于0 jQuery.validator.addMethod("isFloatLtZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value<0; }, "浮点数必须小于0"); // 判断浮点数value是否小于或等于0 jQuery.validator.addMethod("isFloatLteZero", function(value, element) { value=parseFloat(value); return this.optional(element) || value<=0; }, "浮点数必须小于或等于0"); // 判断浮点型 jQuery.validator.addMethod("isFloat", function(value, element) { return this.optional(element) || /^[-\+]?\d+(\.\d+)?$/.test(value); }, "只能包含数字、小数点等字符"); // 匹配integer jQuery.validator.addMethod("isInteger", function(value, element) { return this.optional(element) || (/^[-\+]?\d+$/.test(value) && parseInt(value)>=0); }, "匹配integer"); // 判断数值类型,包括整数和浮点数 jQuery.validator.addMethod("isNumber", function(value, element) { return this.optional(element) || /^[-\+]?\d+$/.test(value) || /^[-\+]?\d+(\.\d+)?$/.test(value); }, "匹配数值类型,包括整数和浮点数"); // 只能输入[0-9]数字 jQuery.validator.addMethod("isDigits", function(value, element) { return this.optional(element) || /^\d+$/.test(value); }, "只能输入0-9数字"); // 判断中文字符 jQuery.validator.addMethod("isChinese", function(value, element) { return this.optional(element) || /^[\u0391-\uFFE5]+$/.test(value); }, "只能包含中文字符。"); // 判断英文字符 jQuery.validator.addMethod("isEnglish", function(value, element) { return this.optional(element) || /^[A-Za-z]+$/.test(value); }, "只能包含英文字符。"); // 手机号码验证 jQuery.validator.addMethod("isMobile", function(value, element) { var length = value.length; return this.optional(element) || (length == 11 && /^(((13[0-9]{1})|(15[0-35-9]{1})|(17[0-9]{1})|(18[0-9]{1}))+\d{8})$/.test(value)); }, "手机号码格式不正确。"); // 电话号码验证 jQuery.validator.addMethod("isPhone", function(value, element) { var tel = /^(\d{3,4}-?)?\d{7,9}$/g; return this.optional(element) || (tel.test(value)); }, "电话号码格式不正确"); // 联系电话(手机/电话皆可)验证 jQuery.validator.addMethod("isTel", function(value,element) { var length = value.length; var mobile = /^(((13[0-9]{1})|(15[0-35-9]{1})|(17[0-9]{1})|(18[0-9]{1}))+\d{8})$/; var tel = /^(\d{3,4}-?)?\d{7,9}$/g; return this.optional(element) || tel.test(value) || (length==11 && mobile.test(value)); }, "请输入正确手机号码或电话号码"); // 匹配qq jQuery.validator.addMethod("isQq", function(value, element) { return this.optional(element) || /^[1-9]\d{4,12}$/; }, "QQ号码不合法"); // 邮政编码验证 jQuery.validator.addMethod("isZipCode", function(value, element) { var zip = /^[0-9]{6}$/; return this.optional(element) || (zip.test(value)); }, "邮政编码不正确"); // 匹配密码,以字母开头,长度在6-16之间,只能包含字符、数字和下划线。 jQuery.validator.addMethod("isPwd", function(value, element) { return this.optional(element) || /^[a-zA-Z]\\w{6,16}$/.test(value); }, "以字母开头,长度在6-12之间,只能包含字符、数字和下划线。"); // 身份证号码验证 jQuery.validator.addMethod("isIdCardNo", function(value, element) { //var idCard = /^(\d{6})()?(\d{4})(\d{2})(\d{2})(\d{3})(\w)$/; return this.optional(element) || isIdCardNo(value); }, "身份证号码不正确"); // IP地址验证 jQuery.validator.addMethod("ip", function(value, element) { return this.optional(element) || /^(([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))\.)(([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))\.){2}([1-9]|([1-9]\d)|(1\d\d)|(2([0-4]\d|5[0-5])))$/.test(value); }, "请填写正确的IP地址"); // 字符验证,只能包含中文、英文、数字、下划线等字符。 jQuery.validator.addMethod("stringCheck", function(value, element) { return this.optional(element) || /^[a-zA-Z0-9\u4e00-\u9fa5-_]+$/.test(value); }, "只能包含中文、英文、数字、下划线等字符"); // 匹配english jQuery.validator.addMethod("isEnglish", function(value, element) { return this.optional(element) || /^[A-Za-z]+$/.test(value); }, "必须输入英文"); // 匹配汉字 jQuery.validator.addMethod("isChinese", function(value, element) { return this.optional(element) || /^[\u4e00-\u9fa5]+$/.test(value); }, "只能输入汉字"); // 匹配中文(包括汉字和字符) jQuery.validator.addMethod("isChineseChar", function(value, element) { return this.optional(element) || /^[\u0391-\uFFE5]+$/.test(value); }, "匹配中文(包括汉字和字符) "); // 判断是否为合法字符(a-zA-Z0-9-_) jQuery.validator.addMethod("isRightfulString", function(value, element) { return this.optional(element) || /^[A-Za-z0-9_-]+$/.test(value); }, "判断是否为合法字符(a-zA-Z0-9-_)"); // 判断是否包含中英文特殊字符,除英文"-_"字符外 jQuery.validator.addMethod("isContainsSpecialChar", function(value, element) { var reg = RegExp(/[(\ )(\`)(\~)(\!)(\@)(\#)(\$)(\%)(\^)(\&)(\*)(\()(\))(\+)(\=)(\|)(\{)(\})(\')(\:)(\;)(\')(',)(\[)(\])(\.)(\<)(\>)(\/)(\?)(\~)(\!)(\@)(\#)(\¥)(\%)(\…)(\&)(\*)(\()(\))(\—)(\+)(\|)(\{)(\})(\【)(\】)(\‘)(\;)(\:)(\”)(\“)(\’)(\。)(\,)(\、)(\?)]+/); return this.optional(element) || !reg.test(value); }, "含有中英文特殊字符"); //车牌号校验 jQuery.validator.addMethod("isPlateNo", function(value, element) { var reg = /^[\u4e00-\u9fa5]{1}[A-Z]{1}[A-Z_0-9]{5}$/; return this.optional(element) || (tel.test(value)); },"请输入正确车牌号");});//身份证号码的验证规则function isIdCardNo(num){ //if (isNaN(num)) {alert("输入的不是数字!"); return false;} var len = num.length, re; if (len == 15) re = new RegExp(/^(\d{6})()?(\d{2})(\d{2})(\d{2})(\d{2})(\w)$/); else if (len == 18) re = new RegExp(/^(\d{6})()?(\d{4})(\d{2})(\d{2})(\d{3})(\w)$/); else { //alert("输入的数字位数不对。"); return false; } var a = num.match(re); if (a != null) { if (len==15) { var D = new Date("19"+a[3]+"/"+a[4]+"/"+a[5]); var B = D.getYear()==a[3]&&(D.getMonth()+1)==a[4]&&D.getDate()==a[5]; } else { var D = new Date(a[3]+"/"+a[4]+"/"+a[5]); var B = D.getFullYear()==a[3]&&(D.getMonth()+1)==a[4]&&D.getDate()==a[5]; } if (!B) { //alert("输入的身份证号 "+ a[0] +" 里出生日期不对。"); return false; } } if(!re.test(num)){ //alert("身份证最后一位只能是数字和字母。"); return false; } return true; } 使用方法为:
$("#editForm").validate({ rules: { familyMemberName: { required: true, cnRangelength: [0,32] }, idCard: { required: true, isIdCardNo:true, }, email: { required: true, email:true }, mobile: { required: true, isPhone:true }, genders:{ required:true }, medicalCard: { required: true }, address: { required: true }, householderrelation:{ required:true }, relationOfHead: { required: true }, healthLabel: { required: true, cnRangelength: [0,100] } },submitHandler:function(form){ form.submit(); } }); });